Basics¶
Operators and Vectors¶
The main objects in rocALUTION are linear operators and vectors. All objects can be moved to an accelerator at run time. The linear operators are defined as local or global matrices (i.e. on a single node or distributed/multi-node) and local stencils (i.e. matrix-free linear operations). The only template parameter of the operators and vectors is the data type (ValueType). The operator data type could be float, double, complex float or complex double, while the vector data type can be int, float, double, complex float or complex double (int is used mainly for the permutation vectors). In the current version, cross ValueType object operations are not supported. Fig. 1 gives an overview of supported operators and vectors. Further details are also given in the Design Documentation.
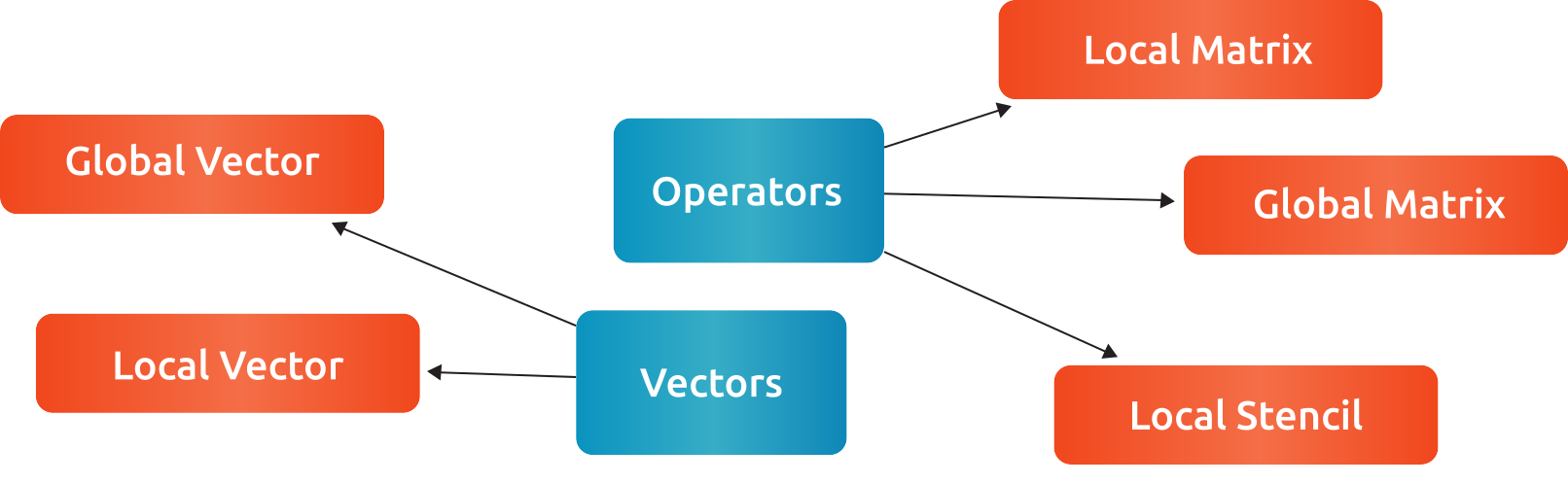
Fig. 1 Operator and vector classes.¶
Each of the objects contain a local copy of the hardware descriptor created by the rocalution::init_rocalution() function. This allows the user to modify it according to his needs and to obtain two or more objects with different hardware specifications (e.g. different amount of OpenMP threads, HIP block sizes, etc.).
Local Operators and Vectors¶
By Local Operators and Vectors we refer to Local Matrices and Stencils and to Local Vectors. By Local we mean the fact that they stay on a single system. The system can contain several CPUs via UMA or NUMA memory system, it can also contain an accelerator.
-
template<typename ValueType>
class LocalMatrix : public rocalution::Operator<ValueType> LocalMatrix class.
A LocalMatrix is called local, because it will always stay on a single system. The system can contain several CPUs via UMA or NUMA memory system or it can contain an accelerator.
A number of matrix formats are supported. These are CSR, BCSR, MCSR, COO, DIA, ELL, HYB, and DENSE.
Note
For CSR type matrices, the column indices must be sorted in increasing order. For COO matrices, the row indices must be sorted in increasing order. The function
Checkcan be used to check whether a matrix contains valid data. For CSR and COO matrices, the functionSortcan be used to sort the row or column indices respectively.- Template Parameters
ValueType – - can be int, float, double, std::complex<float> and std::complex<double>
-
template<typename ValueType>
class LocalStencil : public rocalution::Operator<ValueType> LocalStencil class.
A LocalStencil is called local, because it will always stay on a single system. The system can contain several CPUs via UMA or NUMA memory system or it can contain an accelerator.
- Template Parameters
ValueType – - can be int, float, double, std::complex<float> and std::complex<double>
-
template<typename ValueType>
class LocalVector : public rocalution::Vector<ValueType> LocalVector class.
A LocalVector is called local, because it will always stay on a single system. The system can contain several CPUs via UMA or NUMA memory system or it can contain an accelerator.
- Template Parameters
ValueType – - can be int, float, double, std::complex<float> and std::complex<double>
Global Operators and Vectors¶
By Global Operators and Vectors we refer to Global Matrix and to Global Vectors. By Global we mean the fact they can stay on a single or multiple nodes in a network. For this type of computation, the communication is based on MPI.
-
template<typename ValueType>
class GlobalMatrix : public rocalution::Operator<ValueType> GlobalMatrix class.
A GlobalMatrix is called global, because it can stay on a single or on multiple nodes in a network. For this type of communication, MPI is used.
A number of matrix formats are supported. These are CSR, BCSR, MCSR, COO, DIA, ELL, HYB, and DENSE.
Note
For CSR type matrices, the column indices must be sorted in increasing order. For COO matrices, the row indices must be sorted in increasing order. The function
Checkcan be used to check whether a matrix contains valid data. For CSR and COO matrices, the functionSortcan be used to sort the row or column indices respectively.- Template Parameters
ValueType – - can be int, float, double, std::complex<float> and std::complex<double>
-
template<typename ValueType>
class GlobalVector : public rocalution::Vector<ValueType> GlobalVector class.
A GlobalVector is called global, because it can stay on a single or on multiple nodes in a network. For this type of communication, MPI is used.
- Template Parameters
ValueType – - can be int, float, double, std::complex<float> and std::complex<double>
Backend Descriptor and User Control¶
Naturally, not all routines and algorithms can be performed efficiently on many-core systems (i.e. on accelerators). To provide full functionality, the library has internal mechanisms to check if a particular routine is implemented on the accelerator. If not, the object is moved to the host and the routine is computed there. This guarantees that your code will run (maybe not in the most efficient way) with any accelerator regardless of the available functionality for it.
Initialization of rocALUTION¶
The body of a rocALUTION code is very simple, it should contain the header file and the namespace of the library.
The program must contain an initialization call to init_rocalution which will check and allocate the hardware and a finalizing call to stop_rocalution which will release the allocated hardware.
-
int rocalution::init_rocalution(int rank = -1, int dev_per_node = 1)
Initialize rocALUTION platform.
init_rocalutiondefines a backend descriptor with information about the hardware and its specifications. All objects created after that contain a copy of this descriptor. If the specifications of the global descriptor are changed (e.g. set different number of threads) and new objects are created, only the new objects will use the new configurations.For control, the library provides the following functions
set_device_rocalution() is a unified function to select a specific device. If you have compiled the library with a backend and for this backend there are several available devices, you can use this function to select a particular one. This function has to be called before init_rocalution().
set_omp_threads_rocalution() sets the number of OpenMP threads. This function has to be called after init_rocalution().
- Example
#include <rocalution/rocalution.hpp> using namespace rocalution; int main(int argc, char* argv[]) { init_rocalution(); // ... stop_rocalution(); return 0; }
- Parameters
rank – [in] specifies MPI rank when multi-node environment
dev_per_node – [in] number of accelerator devices per node, when in multi-GPU environment
-
int rocalution::stop_rocalution(void)
Shutdown rocALUTION platform.
stop_rocalutionshuts down the rocALUTION platform.
Thread-core Mapping¶
The number of threads which rocALUTION will use can be modified by the function set_omp_threads_rocalution or by the global OpenMP environment variable (for Unix-like OS this is OMP_NUM_THREADS).
During the initialization phase, the library provides affinity thread-core mapping:
If the number of cores (including SMT cores) is greater or equal than two times the number of threads, then all the threads can occupy every second core ID (e.g. 0,2,4,…). This is to avoid having two threads working on the same physical core, when SMT is enabled.
If the number of threads is less or equal to the number of cores (including SMT), and the previous clause is false, then the threads can occupy every core ID (e.g. 0,1,2,3,…).
If non of the above criteria is matched, then the default thread-core mapping is used (typically set by the operating system).
Note
The thread-core mapping is available for Unix-like operating systems only.
Note
The user can disable the thread affinity by set_omp_affinity_rocalution, before initializing the library.
OpenMP Threshold Size¶
Whenever working on a small problem, OpenMP host backend might be slightly slower than using no OpenMP.
This is mainly attributed to the small amount of work, which every thread should perform and the large overhead of forking/joining threads.
This can be avoid by the OpenMP threshold size parameter in rocALUTION.
The default threshold is set to 10.000, which means that all matrices under (and equal to) this size will use only one thread (disregarding the number of OpenMP threads set in the system).
The threshold can be modified with set_omp_threshold_rocalution.
Accelerator Selection¶
The accelerator device id that is supposed to be used for the computation can be selected by the user by set_device_rocalution.
Disable the Accelerator¶
Furthermore, the accelerator can be disabled without having to re-compile the library by calling disable_accelerator_rocalution.
Backend Information¶
Detailed information about the current backend / accelerator in use as well as the available accelerators can be printed by info_rocalution.
MPI and Multi-Accelerators¶
When initializing the library with MPI, the user need to pass the rank of the MPI process as well as the number of accelerators available on each node. Basically, this way the user can specify the mapping of MPI process and accelerators - the allocated accelerator will be rank % num_dev_per_node. Thus, the user can run two MPI processes on systems with two accelerators by specifying the number of devices to 2, as illustrated in the example code below.
#include <rocalution.hpp>
#include <mpi.h>
using namespace rocalution;
int main(int argc, char* argv[])
{
MPI_Init(&argc, &argv);
MPI_Comm comm = MPI_COMM_WORLD;
int num_processes;
int rank;
MPI_Comm_size(comm, &num_processes);
MPI_Comm_rank(comm, &rank);
int nacc_per_node = 2;
init_rocalution(rank, nacc_per_node);
// ... do some work
stop_rocalution();
return 0;
}
Automatic Object Tracking¶
rocALUTION supports automatic object tracking.
After the initialization of the library, all objects created by the user application can be tracked.
Once stop_rocalution is called, all memory from tracked objects gets deallocated.
This will avoid memory leaks when the objects are allocated but not freed.
The user can enable or disable the tracking by editing src/utils/def.hpp.
By default, automatic object tracking is disabled.
Verbose Output¶
rocALUTION provides different levels of output messages. The VERBOSE_LEVEL can be modified in src/utils/def.hpp before the compilation of the library. By setting a higher level, the user will obtain more detailed information about the internal calls and data transfers to and from the accelerators. By default, VERBOSE_LEVEL is set to 2.
Verbose Output and MPI¶
To prevent all MPI processes from printing information to stdout, the default configuration is that only RANK 0 outputs information. The user can change the RANK or allow all processes to print setting LOG_MPI_RANK to 1 in src/utils/def.hpp. If file logging is enabled, all ranks write into the corresponding log files.
Debug Output¶
Debug output will print almost every detail in the program, including object constructor / destructor, address of the object, memory allocation, data transfers, all function calls for matrices, vectors, solvers and preconditioners. The flag DEBUG_MODE can be set in src/utils/def.hpp. When enabled, additional assert()s are being checked during the computation. This might decrease performance of some operations significantly.
File Logging¶
rocALUTION trace file logging can be enabled by setting the environment variable ROCALUTION_LAYER to 1. rocALUTION will then log each rocALUTION function call including object constructor / destructor, address of the object, memory allocation, data transfers, all function calls for matrices, vectors, solvers and preconditioners. The log file will be placed in the working directory. The log file naming convention is rocalution-rank-<rank>-<time_since_epoch_in_msec>.log. By default, the environment variable ROCALUTION_LAYER is unset, and logging is disabled.
Note
Performance might degrade when logging is enabled.
Versions¶
For checking the rocALUTION version in an application, pre-defined macros can be used:
#define __ROCALUTION_VER_MAJOR // version major
#define __ROCALUTION_VER_MINOR // version minor
#define __ROCALUTION_VER_PATCH // version patch
#define __ROCALUTION_VER_TWEAK // commit id (sha-1)
#define __ROCALUTION_VER_PRE // version pre-release (alpha or beta)
#define __ROCALUTION_VER // version
The final __ROCALUTION_VER holds the version number as 10000 * major + 100 * minor + patch, as defined in src/base/version.hpp.in.